
-


-


-


-

 Delen
Delen
RAG- systemen
Binnen het lectoraat Ambient Intelligence van Saxion zijn we aan de slag gegaan met een vraag die in veel projecten terugkomt: iedereen bouwt RAG-systemen, maar iedereen doet het anders. RAG staat voor Retrieval-Augmented Generation: een architectuur waarbij een taalmodel eerst relevante informatie ophaalt uit een kennisbron en die vervolgens gebruikt om een antwoord te genereren. In de praktijk ontstaan dit soort systemen vaak snel en pragmatisch, met uiteenlopende keuzes in modellen, embeddings en tooling, en weinig samenhang of hergebruik.
In het onderzoek Knowledge Base Hub is onderzocht hoe dit gestructureerder kan. Een belangrijk onderdeel daarbij is retrieval: het ophalen van relevante informatie. Sparse retrieval werkt met exacte termen en trefwoorden en is effectief in domeinen met veel vast vakjargon of coderingen. Dense retrieval gebruikt embeddings om semantische overeenkomsten te vinden en is beter in het meenemen van context, maar minder precies op detailniveau.
Welke aanpak passend is, verschilt per domein en toepassing. Voor vragen waarbij relaties centraal staan, bieden knowledge graphs uitkomst. In industriële omgevingen gaat het bijvoorbeeld om inzicht in gebeurtenissen over X, onder specifieke condities Y, binnen project Z. Deze informatie kan goed worden gemodelleerd in grafen en bevraagd met SPARQL. Tegelijkertijd vraagt dit om extra stappen in de keten: het genereren van queries, het ophalen van gestructureerde data en het vertalen daarvan naar natuurlijke taal. Dat verhoogt de complexiteit en de responstijd. Een vergelijkbaar spanningsveld speelt bij het inzetten van reranker-modellen, die de kwaliteit verbeteren maar extra latency introduceren.
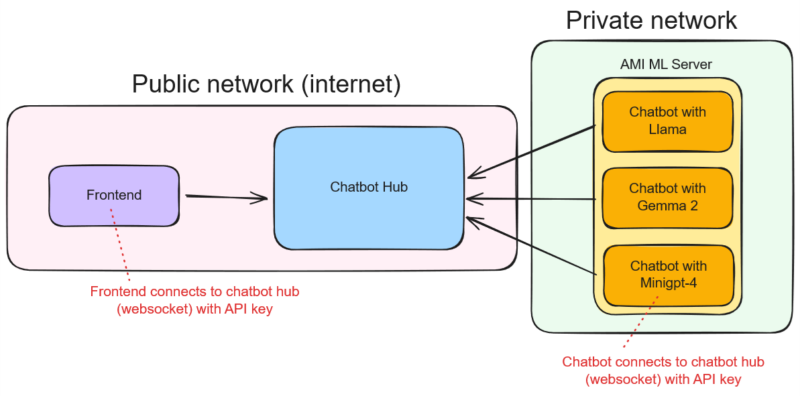
Deze variatie maakt duidelijk dat elke RAG-oplossing anders is. De ontwikkelde hub orchestrator speelt hierop in. De hub fungeert als centrale regielaag waarin keuzes over retrieval strategie, ranking, prompts en taalmodellen expliciet worden gemaakt en uitwisselbaar zijn. Via API’s en websockets kunnen verschillende frontends worden aangesloten, terwijl taalmodellen, kennisbronnen en rag-systemen op uiteenlopende locaties kunnen draaien, bijvoorbeeld op
private servers of binnen afgeschermde omgevingen. Hierdoor ontstaat één centrale plek voor orchestratie, logging en governance, terwijl de uitvoering modulair blijft. Dat maakt het mogelijk om RAG-systemen per use-case te optimaliseren zonder de architectuur telkens opnieuw op te bouwen.
